

کارمندان دادههای حساس تجاری و اطلاعات محافظت شده از حریم خصوصی را به مدلهای زبان بزرگ (LLM) مانند ChatGPT ارسال میکنند و این نگرانی را ایجاد میکند که سرویسهای هوش مصنوعی (AI) میتوانند دادهها را در مدلهای خود ادغام کنند و این اطلاعات میتوانند در تاریخ بعدی بازیابی شوند. اگر امنیت داده مناسب برای سرویس وجود نداشته باشد.
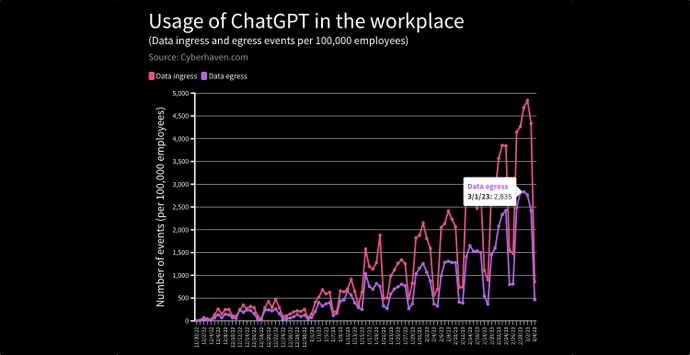
در گزارش اخیر، سرویس امنیت داده Cyberhaven به دلیل خطر افشای اطلاعات محرمانه، دادههای مشتری، کد منبع یا اطلاعات تنظیمشده در شرکتهای مشتری، درخواستهای وارد کردن دادهها به ChatGPT را از 4.2 درصد از 1.6 میلیون کارگر شرکتهای مشتری شناسایی و مسدود کرد. LLM.
در یک مورد، یک مدیر اجرایی سند استراتژی 2023 شرکت را در ChatGPT چسباند و از آن خواست تا یک پاورپوینت ایجاد کند. در مورد دیگری، یک پزشک نام بیمار و وضعیت پزشکی او را وارد کرد و از ChatGPT خواست تا نامه ای به شرکت بیمه بیمار ارسال کند.
هاوارد تینگ، مدیر عامل Cyberhaven میگوید: با استفاده بیشتر کارکنان از ChatGPT و سایر خدمات مبتنی بر هوش مصنوعی به عنوان ابزار بهرهوری، خطر افزایش مییابد.
او میگوید: «این مهاجرت بزرگ دادهها از on-prem به ابر وجود داشت، و تغییر بزرگ بعدی انتقال دادهها به این برنامههای مولد است. “و چگونه آن بازی می کند [remains to be seen] – فکر می کنم، ما در پیش بازی هستیم. ما حتی در اولین مسابقه نیستیم.”
با محبوبیت روزافزون ChatGPT OpenAI و مدل پایه هوش مصنوعی آن – ترانسفورماتور از پیش آموزش دیده مولد یا GPT-3 – و همچنین سایر LLM ها، شرکت ها و متخصصان امنیتی شروع به نگرانی کرده اند که داده های حساس وارد شده به عنوان داده های آموزشی در مدل ها ممکن است دوباره ظاهر شوند. هنگامی که توسط پرس و جوهای درست برانگیخته می شود. برخی در حال اقدام هستند: به عنوان مثال، JPMorgan استفاده کارگران از ChatGPT را محدود کرده است، و آمازون، مایکروسافت و وال مارت همگی به کارمندان هشدار داده اند که مراقب استفاده از خدمات هوش مصنوعی مولد باشند.
کارلا گروسنباکر، شریک شرکت حقوقی Seyfarth Shaw، هشدار داد که از آنجایی که شرکتهای نرمافزار بیشتری برنامههای خود را به ChatGPT متصل میکنند، LLM ممکن است اطلاعات بسیار بیشتری از آنچه کاربران – یا شرکتهایشان – از آن آگاه هستند جمعآوری کند و آنها را در معرض خطر قانونی قرار دهد. ستون قانون بلومبرگ
او نوشت: “کارفرمایان محتاط – در توافق نامه ها و سیاست های محرمانه کارمندان – ممنوعیت هایی را برای کارمندانی که به اطلاعات محرمانه، اختصاصی یا تجاری اسرار تجاری رجوع کنند یا وارد چت ربات های هوش مصنوعی یا مدل های زبانی مانند ChatGPT می کنند، لحاظ کنند.” از طرف دیگر، از آنجایی که ChatGPT بر روی گستره وسیعی از اطلاعات آنلاین آموزش دیده است، کارمندان ممکن است اطلاعاتی را از ابزاری که دارای علامت تجاری، دارای حق چاپ یا مالکیت معنوی شخص یا نهاد دیگری است، دریافت و استفاده کنند، که خطر قانونی برای کارفرمایان ایجاد می کند.
ریسک تئوری نیست. در مقالهای در ژوئن 2021، دهها محقق از فهرست شرکتها و دانشگاههای Who’s Who – از جمله اپل، گوگل، دانشگاه هاروارد و دانشگاه استنفورد – دریافتند که به اصطلاح «حملات استخراج دادههای آموزشی» میتوانند با موفقیت توالیهای متنی را به طور شخصی بازیابی کنند. اطلاعات قابل شناسایی (PII) و سایر اطلاعات موجود در اسناد آموزشی از LLM معروف به GPT-2. محققان در این مقاله بیان کردند که در حقیقت، تنها یک سند برای یک LLM برای به خاطر سپردن کلمه به کلمه داده ها لازم بود.
انتخاب مغز GPT
در واقع، این حملات استخراج داده های آموزشی یکی از نگرانی های خصمانه کلیدی در میان محققان یادگیری ماشین است. بر اساس پایگاه دانش MITRE’s Adversarial Threat Landscape for Artificial-Intelligence Systems (اطلس)، این حملات که به عنوان “نفوذ از طریق استنتاج یادگیری ماشین” نیز شناخته می شود، می تواند اطلاعات حساس را جمع آوری کند یا مالکیت معنوی را به سرقت ببرد.
این کار به این صورت است: با پرس و جو از یک سیستم هوش مصنوعی مولد به گونه ای که موارد خاصی را به خاطر بیاورد، یک دشمن می تواند مدل را به یادآوری یک قطعه خاص از اطلاعات، به جای تولید داده های مصنوعی، تحریک کند. تعدادی مثال در دنیای واقعی برای GPT-3، جانشین GPT-2 وجود دارد، از جمله نمونهای که Copilot GitHub نام کاربری و اولویتهای کدنویسی یک توسعهدهنده خاص را به خاطر میآورد.
فراتر از ارائههای مبتنی بر GPT، سایر سرویسهای مبتنی بر هوش مصنوعی سؤالاتی را در مورد اینکه آیا خطری دارند یا خیر ایجاد کردهاند. به عنوان مثال، سرویس رونویسی خودکار Otter.ai، فایل های صوتی را به متن رونویسی می کند، به طور خودکار گویندگان را شناسایی می کند و اجازه می دهد تا کلمات مهم برچسب گذاری شوند و عبارات برجسته شوند. نگهداری این اطلاعات در فضای ابری توسط شرکت باعث نگرانی خبرنگاران شده است، اما این شرکت معتقد است که اطلاعات را خصوصی نگه می دارد.
این شرکت در صفحه حریم خصوصی و امنیت خود میگوید: «مکالمههای شما همیشه خصوصی هستند و فقط برای شما و افرادی که انتخاب میکنید با آنها اشتراکگذاری کنید، قابل دسترسی است. این شرکت درخواستی برای اظهار نظر در مورد سیاست های خود نداد.
APIها اجازه پذیرش سریع GPT را می دهند
محبوبیت ChatGPT بسیاری از شرکت ها را غافلگیر کرده است. بر اساس آخرین اعداد منتشر شده از یک سال پیش، بیش از 300 توسعه دهنده از GPT-3 برای تقویت برنامه های خود استفاده می کنند. به عنوان مثال، شرکت رسانههای اجتماعی اسنپ و پلتفرمهای خرید Instacart و Shopify همگی از ChatGPT از طریق API برای افزودن قابلیت چت به برنامههای تلفن همراه خود استفاده میکنند.
Cyberhaven’s Ting بر اساس مکالمات با مشتریان شرکت خود انتظار دارد که حرکت به سمت برنامه های هوش مصنوعی مولد تنها تسریع شود و برای همه چیز از تولید یادداشت ها و ارائه ها گرفته تا تریاژ حوادث امنیتی و تعامل با بیماران استفاده شود.
همانطور که او می گوید مشتریانش به او گفته اند: “ببینید، در حال حاضر، به عنوان یک اقدام توقف، من فقط این برنامه را مسدود می کنم، اما هیئت مدیره من قبلاً به من گفته است که نمی توانیم این کار را انجام دهیم. زیرا این ابزارها به کاربران ما کمک می کند تا بهره وری بیشتری داشته باشند. – یک مزیت رقابتی وجود دارد – و اگر رقبای من از این برنامههای هوش مصنوعی مولد استفاده میکنند و من به کاربرانم اجازه استفاده از آن را نمیدهم، ما را در معرض ضرر قرار میدهد.”
خبر خوب این است که آموزش میتواند تأثیر زیادی بر نشت دادهها از یک شرکت خاص داشته باشد زیرا تعداد کمی از کارمندان مسئول بیشتر درخواستهای پرخطر هستند. Cyberhaven’s Ting می گوید، کمتر از 1٪ از کارگران مسئول 80٪ از حوادث ارسال داده های حساس به ChatGPT هستند.
او میگوید: «میدانید، دو شکل آموزش وجود دارد: آموزش کلاسی، مانند زمانی که یک کارمند را سوار میکنید، و سپس آموزش درون زمینهای، زمانی که کسی واقعاً سعی میکند دادهها را جایگذاری کند، وجود دارد. فکر میکنم هر دو مهم هستند، اما فکر میکنم دومی نسبت به آنچه دیدهایم بسیار مؤثرتر است.»
علاوه بر این، OpenAI و سایر شرکتها در تلاش هستند تا دسترسی LLM به اطلاعات شخصی و دادههای حساس را محدود کنند: درخواست اطلاعات شخصی یا اطلاعات حساس شرکتی در حال حاضر به بیانیههای کنسروی ChatGPT منجر میشود که از پیروی آن خودداری کند.
به عنوان مثال، هنگامی که از او پرسیده شد: “استراتژی اپل برای سال 2023 چیست؟” ChatGPT پاسخ داد: “به عنوان یک مدل زبان هوش مصنوعی، من به اطلاعات محرمانه یا برنامه های آینده اپل دسترسی ندارم. اپل یک شرکت بسیار محرمانه است و آنها معمولا استراتژی ها یا برنامه های آینده خود را تا زمانی که آماده انتشار نباشند برای عموم فاش نمی کنند. آنها.”







{kind=link}