


(SuPatMaN/Shutterstock)
معمولاً برای به دست آوردن یک پاسخ چند جانبه از پایگاه داده تحلیلی پرسرعت Kinetica که توسط پردازندههای گرافیکی پشتیبانی میشود، اما به صورت سیمی با Postgres سازگار است، نیاز به کمی SQL پیچیده است. اما با رابط زبان طبیعی جدید ChatGPT که امروز رونمایی شد، کاربران غیر فنی می توانند پاسخ سوالات پیچیده ای را که به زبان انگلیسی ساده نوشته شده است، دریافت کنند.
Kinetica بیش از یک دهه پیش توسط ارتش ایالات متحده انکوبه شد تا از میان تپههای عظیم دادههای مکانی و زمانی در حال حرکت سریع در جستجوی فعالیتهای تروریستی سرازیر شود. با استفاده از قابلیت پردازش پردازندههای گرافیکی، پایگاه داده برداری میتوانست اسکنهای کامل جدول را روی دادهها اجرا کند، در حالی که سایر پایگاههای داده مجبور شدند دادهها را با نمایهها و تکنیکهای دیگر حذف کنند (از آن زمان CPUها را با AVX-512 اینتل پذیرفتند).
با راه اندازی امروز ویژگی جدید Conversational Query، قابلیت پردازش عظیم Kinetica اکنون در دسترس کارگرانی است که توانایی نوشتن پرس و جوهای پیچیده SQL را ندارند. دموکراتیک کردن دسترسی به این معنی است که مدیران اجرایی و سایر افراد با پرسشهای دادههای موقت اکنون میتوانند از قدرت پایگاه داده Kinetica برای دریافت پاسخ استفاده کنند.
نیما نگهبان، یکی از بنیانگذاران و مدیرعامل کینتیکا، می گوید که اکثر پرس و جوهای پایگاه داده برنامه ریزی شده اند، که به سازمان ها امکان می دهد فهرست ها بنویسند، داده ها را از حالت عادی خارج کنند، یا تجمیع ها را از قبل محاسبه کنند تا این پرس و جوها به شیوه ای کارآمد اجرا شوند.
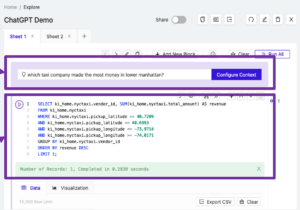
کاربر میتواند یک درخواست زبان طبیعی را مستقیماً در داشبورد Kinetica ارسال کند که ChatGPT آن را برای اجرا به SQL تبدیل میکند.
نگاهبان میگوید: «با ظهور مدلهای زبان بزرگ، ما فکر میکنیم که این ترکیب به جایی تغییر میکند که بخش بزرگتری از آن به درخواستهای موقتی تبدیل میشود». دیتانامی. این واقعاً بهترین کاری است که ما انجام میدهیم، این است که پرس و جوی پیچیده و موقتی را در برابر مجموعه دادههای بزرگ انجام دهیم، زیرا ما این توانایی را داریم که اسکنهای بزرگ انجام دهیم و از دستگاههای محاسباتی چند هستهای بهتر از سایر پایگاههای داده استفاده کنیم.»
Conversational Query با تبدیل پرس و جو زبان طبیعی کاربر به SQL کار می کند. این تبدیل SQL توسط مدل زبان بزرگ ChatGPT (LLM) OpenAI انجام میشود، که ثابت کرد زبان گفتاری، کامپیوتری و غیره را سریع یاد میگیرد. OpenAI API سپس SQL نهایی شده را برمی گرداند و کاربران می توانند آن را مستقیماً از داشبورد Kinetica در مقابل پایگاه داده اجرا کنند.
Kinetica برای درک مقصود زبان بر مدل ChatGPT تکیه کرده است، چیزی که در آن بسیار خوب است. به عنوان مثال، برای پاسخ به این سوال “مردم کجا بیشتر معاشرت می کنند؟” ChatGPT از یک پایگاه داده عظیم از داده های مکانی حرکت انسان، به اندازه کافی هوشمند است که بداند “هنگ اوت” مترادفی برای “زمان سکونت” است، به این ترتیب داده ها به طور رسمی در پایگاه داده شناسایی می شوند. (پاسخ، اتفاقاً 7-11 است.)
Chad Meley، مدیر ارشد بازاریابی Kinetica میگوید که Kinetica همچنین در حال انجام برخی کارها از قبل برای آماده کردن ChatGPT برای تولید SQL خوب از طریق فرآیند “هیدراتاسیون” است.
Meley می گوید: “ما توابع تحلیلی بومی داریم که از طریق SQL قابل فراخوانی هستند و ChatGPT، از طریق بخشی از فرآیند هیدراتاسیون، از آن آگاه می شود.” بنابراین میتواند از یک پیوستن سری زمانی خاص یا پیوستن فضایی استفاده کند که ما ChatGPT از آن آگاه میکنیم. به این ترتیب، ما از توابع معمولی ANSI SQL شما فراتر می رویم.”
SQL تولید شده توسط ChatGPT کامل نیست. همانطور که بسیاری می دانند، LLM مستعد دیدن چیزهایی در داده ها است، به اصطلاح مشکل “توهم”. نگاهبان که در سال 2018 بود میگوید اگرچه SQL کاملاً عاری از نقص نیست، ChatGPT هنوز در این حالت کاملاً مفید است. دیتانامی شخصی برای تماشا.
او می گوید: «من دیده ام که به اندازه کافی خوب است. “اینطور نبوده است [wildly] در هر درخواستی که ایجاد می کند اشتباه است … فکر می کنم با GPT-4 بهتر خواهد بود.![]()
در تجزیه و تحلیل نهایی، زمانی که یک SQL pro طول می کشد تا اتصال هفت طرفه کامل را بنویسد و آن را به پایگاه داده برساند، ممکن است فرصت عمل بر روی داده ها از بین برود. نگاهبان میگوید به همین دلیل است که جفتسازی یک مولد پرس و جو «به اندازه کافی خوب» با پایگاه دادهای به قدرتمندی Kinetica میتواند برای تصمیمگیرندگان متفاوت باشد.
او میگوید: «داشتن موتوری مانند Kinetica که میتواند بدون نیاز به برنامهریزی از قبل، کاری را با آن جستجو انجام دهد»، او میگوید. اگر سعی کنید برخی از این پرس و جوها را با Snowflake انجام دهید، یا پایگاه داده du jour خود را وارد کنید، آنها واقعاً با مشکل مواجه می شوند زیرا این چیزی نیست که برای آن ساخته شده اند. آنها در چیزهای دیگر خوب هستند. چیزی که ما به عنوان یک موتور واقعاً در آن مهارت داریم این است که بدون توجه به پیچیدگی، بدون توجه به تعداد جداول درگیر، پرس و جوهای موردی را انجام دهیم. به طوری که واقعاً به خوبی با این توانایی برای هر کسی که بتواند SQL را در تمام داده های خود ایجاد کند و در مورد تمام داده های شرکت خود سؤال بپرسد، جفت می شود.
Conversational Query اکنون در نسخههای ابری و نسخههای اولیه Kinetica در دسترس است.
آیتم های مرتبط:
ChatGPT به عنوان مهارت مورد نیاز در محل کار برتر است: گزارش Udemy
بانک صدها گره استریم اسپارک را با کینتیکا جایگزین می کند
جلوگیری از هدف بعدی 9/11 انبار داده جریانی جدید NORAD
تجزیه و تحلیل ad hoc، Allen NLP، ChatGPT، Conversational Query، denormalization، GPU، پایگاه داده GPU، نمایه، اتصال چند طرفه، پردازش زبان طبیعی، تولید زبان طبیعی، نیما نگاهان، NLP، پیش تجمع، تولید SQL







{kind=link}