

تصویر توسط نویسنده
درست زمانی که فکر کردیم اخبار کافی درباره مدلهای زبان بزرگ (LLM) را هضم کردهایم، تیم تحقیقات آسیایی Microsoft Visual ChatGPT را برای ما آورد. Visual ChatGPT بر محدودیتهای کنونی ChatGPT غلبه میکند که نمیتواند اطلاعات بصری را پردازش کند زیرا با یک روش زبانی واحد آموزش داده میشود.
Visual ChatGPT سیستمی است که از مدل های Visual Foundation (VFM) برای کمک به ChatGPT برای درک بهتر، تولید و ویرایش اطلاعات بصری استفاده می کند. VFM توانایی تعیین فرمت های ورودی-خروجی، تبدیل اطلاعات بصری به فرمت زبان و مدیریت تاریخچه ها، اولویت ها و تضادهای VFM را دارد.
بنابراین، Visual ChatGPT یک مدل هوش مصنوعی است که به عنوان پلی بین محدودیتهای ChatGPT عمل میکند و به کاربران اجازه میدهد از طریق چت ارتباط برقرار کنند و تصاویر بصری تولید کنند.
محدودیت های ChatGPT
ChatGPT در اکثر مکالمات مردم در چند هفته و چند ماه گذشته بوده است. اما به دلیل قابلیت های آموزشی زبانی، امکان پردازش و تولید تصاویر را نمی دهد.
در حالی که شما مدل های پایه بصری مانند Visual Transformers و Steady Diffusion دارید که قابلیت های بصری شگفت انگیزی دارند. اینجاست که ترکیبی از زبان و مدل های تصویر، Visual ChatGPT را ایجاد کرده است.
مدل های Visual Foundation چیست؟
Visual Foundation Models برای گروه بندی الگوریتم های اساسی که در بینایی کامپیوتر استفاده می شوند استفاده می شود. آنها مهارتهای بینایی کامپیوتری استاندارد را میگیرند و آنها را به برنامههای هوش مصنوعی منتقل میکنند تا با کارهای پیچیدهتر مقابله کنند.
Prompt Manager در Visual ChatGPT از 22 VFM تشکیل شده است که شامل Text-to-Image، ControlNet، Edge-To-Image و غیره است. این به ChatGPT کمک می کند تا تمام سیگنال های بصری یک تصویر را به زبان ChatGPT تبدیل کند تا بهتر درک شود. بنابراین Visual ChatGPT چگونه کار می کند؟
Visual ChatGPT از اجزای مختلفی تشکیل شده است تا به مدل زبان بزرگ ChatGPT کمک کند تا تصاویر بصری را درک کند.
اجزای معماری Visual ChatGPT
- پرس و جو کاربر: اینجا جایی است که کاربر درخواست خود را ارسال می کند
- مدیر سریع: این پرس و جوهای بصری کاربران را به فرمت زبان تبدیل می کند تا مدل ChatGPT قابل درک باشد.
- مدل های بنیاد بصری: این ترکیبی از انواع VFM ها، مانند BLIP (Bootstrapping Language-Image Pre-training)، Stable Diffusion، ControlNet، Pix2Pix و غیره است.
- اصل سیستم: این قوانین اساسی و الزامات Visual ChatGPT را فراهم می کند.
- تاریخچه دیالوگ: این اولین نقطه تعامل و مکالمه ای است که سیستم با کاربر دارد.
- تاریخچه استدلال: این از استدلال قبلی استفاده می کند که VFM های مختلف در گذشته برای حل پرس و جوهای پیچیده داشته اند.
- پاسخ متوسط: با استفاده از VFM ها، مدل سعی می کند چندین پاسخ میانی را که دارای درک منطقی هستند، خروجی دهد.
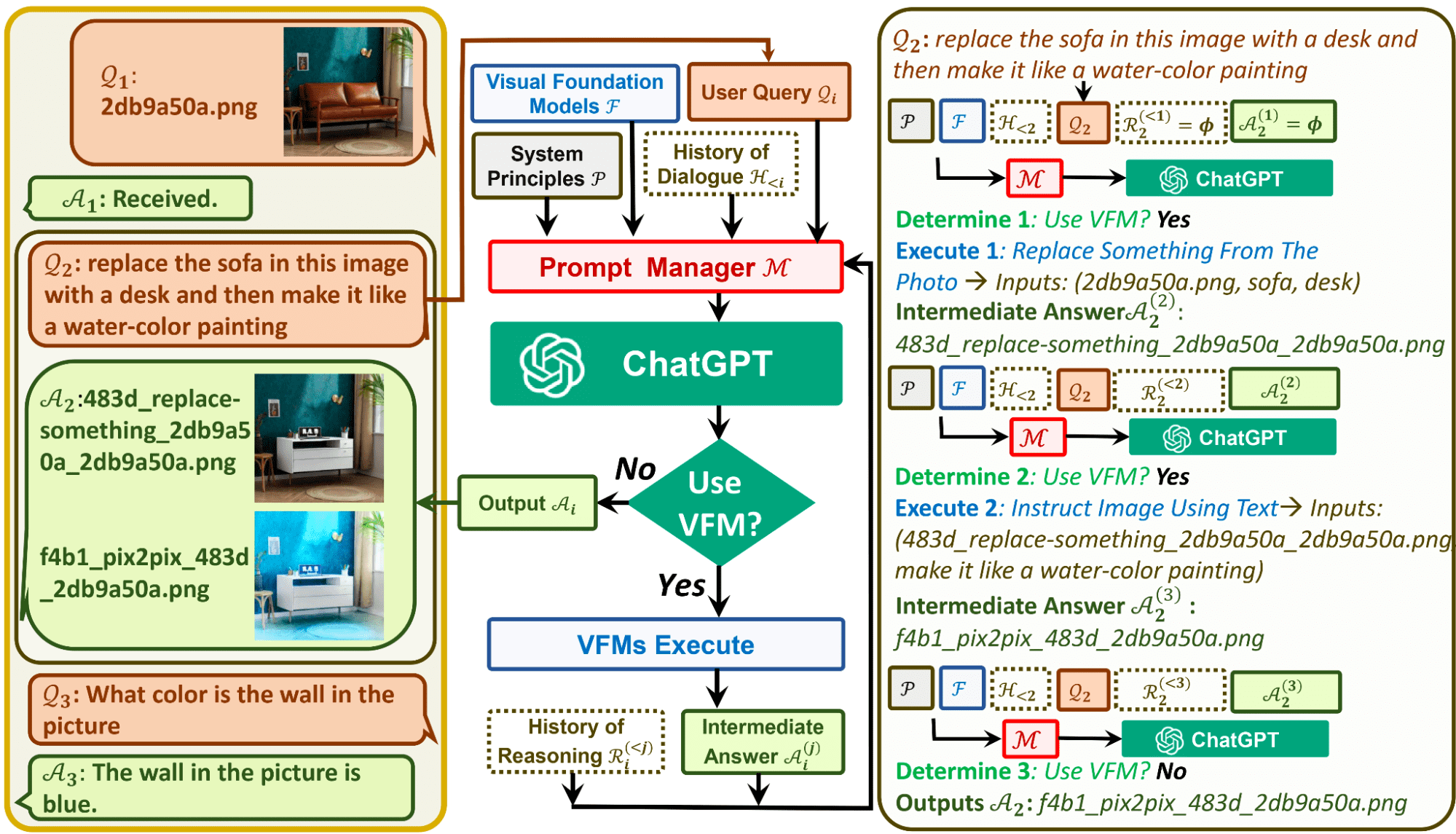
تصویر توسط Microsoft GitHub
اطلاعات بیشتر درباره Prompt Manager
ممکن است برخی از شما فکر کنید که این یک راهحل اجباری برای ChatGPT برای مقابله با تصاویر بصری است، زیرا هنوز همه سیگنالهای بصری یک تصویر را به زبان تبدیل میکند. هنگام آپلود تصاویر، Prompt Manager یک تاریخچه چت داخلی را ترکیب می کند که شامل اطلاعاتی مانند نام فایل است تا ChatGPT بهتر بفهمد که پرس و جو به چه چیزی اشاره دارد.
به عنوان مثال، نام یک تصویر وارد شده توسط کاربر به عنوان یک تاریخچه عملیات عمل می کند و سپس مدیر سریع به مدل کمک می کند تا از طریق “Reasoning Format” عبور کند تا بفهمد چه کاری باید با تصویر انجام شود. قبل از اینکه ChatGPT عملکرد صحیح VFM را انتخاب کند، می توانید این را به عنوان افکار درونی مدل در نظر بگیرید.
در تصویر زیر می بینید که چگونه Prompt Manager قوانین Visual ChatGPT را آغاز می کند:
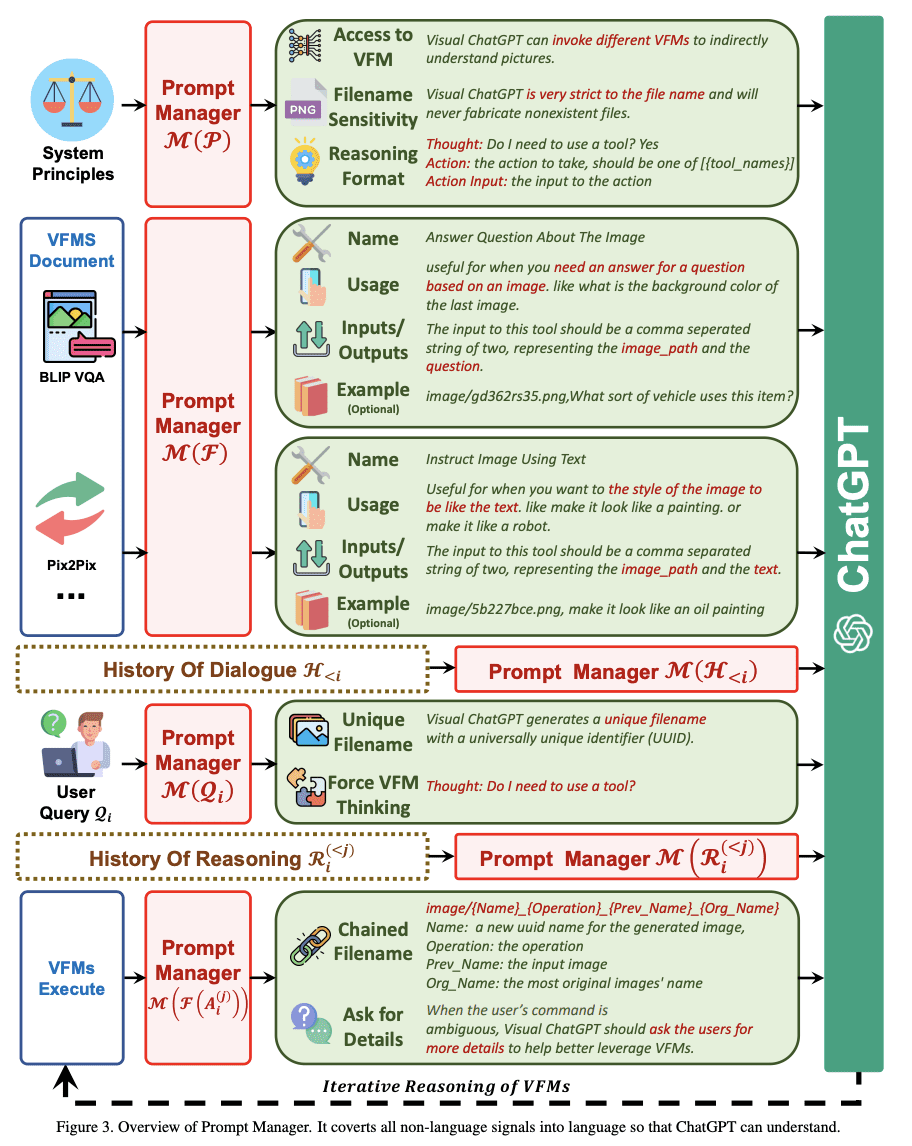
تصویر توسط Visual ChatGPT: صحبت کردن، طراحی و ویرایش با مدل های Visual Foundation
برای شروع سفر Visual ChatGPT خود، ابتدا باید نسخه نمایشی Visual ChatGPT را اجرا کنید:
# create a new environment
conda create -n visgpt python=3.8
# activate the new environment
conda activate visgpt
# prepare the basic environments
pip install -r requirement.txt
# download the visual foundation models
bash download.sh
# prepare your private openAI private key
export OPENAI_API_KEY={Your_Private_Openai_Key}
# create a folder to save images
mkdir ./image
# Start Visual ChatGPT !
python visual_chatgpt.pyهمچنین میتوانید درباره گیتهاب Visual ChatGPT مایکروسافت اطلاعات بیشتری کسب کنید. اطمینان حاصل کنید که به استفاده از حافظه GPU آنها در هر یک از مدل های Visual Foundation نگاه می کنید.
بنابراین Visual ChatGPT چه کاری می تواند انجام دهد؟
تولید تصویر
میتوانید از Visual ChatGPT بخواهید که با ارائه توضیحات، یک تصویر از ابتدا ایجاد کند. بسته به قدرت محاسباتی موجود، تصویر شما در عرض چند ثانیه تولید خواهد شد. تولید تصویر مصنوعی آن با استفاده از داده های متنی مبتنی بر انتشار پایدار است.
تغییر پس زمینه تصویر
باز هم، با استفاده از انتشار پایدار، Visual ChatGPT می تواند پس زمینه تصویر ورودی شما را تغییر دهد. کاربر میتواند هر توضیحی در مورد آنچه که میخواهد پسزمینه به چه چیزی تغییر کند، به دستیار ارائه دهد و مدل انتشار پایدار پسزمینه تصویر را نقاشی میکند.
تغییر تصویر رنگی و جلوه های دیگر
همچنین میتوانید رنگ تصویر خود را تغییر دهید و بر اساس ارائه توضیحات برنامه، افکتها را اعمال کنید. Visual ChatGPT از انواع مدل های از پیش آموزش دیده و OpenCV برای تغییر رنگ تصویر، برجسته کردن لبه های یک تصویر و موارد دیگر استفاده می کند.
ایجاد تغییرات در یک تصویر
Visual ChatGPT به شما این امکان را می دهد که با ویرایش و اصلاح اشیاء در تصویر با توضیحات متنی هدایت شده به برنامه، جنبه هایی از تصویر خود را حذف یا جایگزین کنید. با این حال، خوب است توجه داشته باشید که این ویژگی به قدرت محاسباتی بیشتری نیاز دارد.
همانطور که می دانیم، همیشه نوعی نقص وجود دارد که سازمان ها باید برای بهبود خدمات خود روی آنها کار کنند.
ترکیبی از بینایی کامپیوتری و مدل های زبان بزرگ
Visual ChatGPT به شدت به ChatGPT و VFM ها وابسته است، بنابراین، دقت و قابلیت اطمینان این جنبه های فردی بر عملکرد Visual ChatGPT تأثیر می گذارد. ترکیبی از استفاده از یک مدل زبان بزرگ و چشم انداز کامپیوتری به مقدار زیادی مهندسی سریع نیاز دارد و دستیابی به عملکرد ماهر می تواند دشوار باشد.
حریم خصوصی و امنیت
Visual ChatGPT این قابلیت را دارد که VFM ها را به راحتی وصل و جدا کند، که ممکن است برای برخی از کاربران در مورد نگرانی های امنیتی و حفظ حریم خصوصی نگران کننده باشد. مایکروسافت باید بیشتر بررسی کند که چگونه داده های حساس به خطر نمی افتد.
ماژول خود اصلاحی
یکی از محدودیت هایی که محققان Visual ChatGPT با آن مواجه شدند، نتایج ناسازگار تولید شده به دلیل شکست VFM ها و تنوع درخواست ها بود. بنابراین، آنها به این نتیجه رسیدند که باید روی یک ماژول خود تصحیح کار کنند که اطمینان حاصل کند که خروجی های تولید شده مطابق با آنچه کاربر درخواست کرده است و قادر به انجام اصلاحات لازم است.
مقدار بالای GPU مورد نیاز
برای بهره مندی از Visual ChatGPT و استفاده از 22 VFM، به مقدار زیادی رم GPU، به عنوان مثال A100، نیاز دارید. بسته به وظیفه ای که در دست دارید، اطمینان حاصل کنید که متوجه شده اید چقدر GPU برای انجام موثر کار مورد نیاز است.
Visual ChatGPT هنوز محدودیت های خود را دارد، با این حال این یک پیشرفت بزرگ در استفاده از مدل های زبان بزرگ و Computer Vision به طور همزمان است. اگر می خواهید درباره Visual ChatGPT بیشتر بدانید، این مقاله را بخوانید: Visual ChatGPT: صحبت کردن، طراحی و ویرایش با مدل های Visual Foundation
آیا Visual ChatGPT شبیه ChatGPT4 است؟ اگر این دو را امتحان کرده اید، نظر شما چیست؟ در زیر نظر بدهید!
نیشا آریا دانشمند داده، نویسنده فنی آزاد و مدیر انجمن در KDnuggets است. او به ویژه علاقه مند به ارائه مشاوره شغلی یا آموزش های علم داده و دانش مبتنی بر نظریه در مورد علم داده است. او همچنین مایل است راههای مختلفی را که هوش مصنوعی میتواند به طول عمر انسان کمک کند، کشف کند. یک یادگیرنده مشتاق که به دنبال گسترش دانش فنی و مهارت های نوشتاری خود است و در عین حال به راهنمایی دیگران کمک می کند.







{kind=link}