

Ars Technica
اشیا در سرزمین هوش مصنوعی با سرعت رعد و برق در حال حرکت هستند. روز جمعه، یک توسعهدهنده نرمافزار به نام Georgi Gerganov ابزاری به نام “llama.cpp” ایجاد کرد که میتواند مدل جدید زبان بزرگ هوش مصنوعی کلاس GPT-3 متا، LLaMA را به صورت محلی روی لپتاپ مک اجرا کند. به زودی پس از آن، مردم نحوه اجرای LLaMA را در ویندوز نیز بررسی کردند. سپس کسی آن را در حال اجرا نشان داد روی گوشی پیکسل 6 و بعد آمد یک رزبری پای (البته خیلی آهسته اجرا می شود).
اگر این روند ادامه پیدا کند، ممکن است قبل از اینکه بدانیم به یک رقیب جیبی ChatGPT نگاه می کنیم.
اما بیایید یک دقیقه پشتیبان بگیریم، زیرا هنوز به آنجا نرسیده ایم. (حداقل نه امروز – مثل امروز، 13 مارس 2023.) اما هیچ کس نمی داند که هفته آینده چه خواهد شد.
از زمان راهاندازی ChatGPT، برخی از افراد از محدودیتهای داخلی مدل هوش مصنوعی که مانع از بحث درباره موضوعاتی میشود که OpenAI حساس میداند، ناامید شدهاند. بنابراین رویای یک مدل زبان بزرگ منبع باز (LLM) آغاز شد که هر کسی بتواند بدون سانسور و بدون پرداخت هزینه های API به OpenAI به صورت محلی اجرا کند.
راهحلهای منبع باز وجود دارند (مانند GPT-J)، اما نیاز به مقدار زیادی رم و فضای ذخیرهسازی GPU دارند. سایر جایگزین های منبع باز نمی توانند عملکرد سطح GPT-3 را در سخت افزار سطح مصرف کننده به راحتی در دسترس داشته باشند.
LLaMA را وارد کنید، یک LLM که در اندازه پارامترهای مختلف از 7B تا 65B موجود است (که “B” مانند “میلیارد پارامترها” است، که اعداد ممیز شناور ذخیره شده در ماتریس هایی هستند که نشان دهنده آنچه مدل “می داند” است). LLaMA ادعای سراسیمهای داشت: اینکه مدلهای سایز کوچکتر آن میتوانند با GPT-3 OpenAI، مدل پایهای که ChatGPT را قدرت میدهد، در کیفیت و سرعت خروجیاش مطابقت داشته باشند. فقط یک مشکل وجود داشت – متا کد LLaMA را منبع باز منتشر کرد، اما “وزن” (“دانش” آموزش دیده ذخیره شده در یک شبکه عصبی) را فقط برای محققان واجد شرایط نگه داشت.
پرواز با سرعت LLaMA
محدودیت های متا در LLaMA زیاد دوام نیاورد، زیرا در 2 مارس، شخصی وزن های LLaMA را در BitTorrent فاش کرد. از آن زمان، یک انفجار توسعه در اطراف LLaMA وجود دارد. محقق مستقل هوش مصنوعی Simon Willison این وضعیت را با انتشار Stable Diffusion، یک مدل سنتز تصویر منبع باز که در اوت گذشته عرضه شد، مقایسه کرده است. این چیزی است که او در پستی در وبلاگ خود نوشت:
به نظر من آن لحظه انتشار پایدار در ماه آگوست، کل موج جدید علاقه به هوش مصنوعی مولد را آغاز کرد – که سپس با انتشار ChatGPT در پایان نوامبر به بیش از حد فشار داده شد.
آن لحظه انتشار پایدار در حال حاضر برای مدلهای زبان بزرگ – فناوری پشت سر خود ChatGPT – دوباره اتفاق میافتد. امروز صبح برای اولین بار یک مدل زبان کلاس GPT-3 را روی لپ تاپ شخصی خودم اجرا کردم!
چیزهای هوش مصنوعی قبلاً عجیب بودند. قرار است خیلی عجیب تر شود.
به طور معمول، اجرای GPT-3 به چندین پردازنده گرافیکی A100 کلاس مرکز داده نیاز دارد (همچنین، وزنهای GPT-3 عمومی نیستند)، اما LLaMA موجهایی ایجاد کرد زیرا میتوانست روی یک پردازنده گرافیکی مصرفکننده واحد اجرا شود. و اکنون، با بهینهسازیهایی که اندازه مدل را با استفاده از تکنیکی به نام کوانتیزاسیون کاهش میدهد، LLaMA میتواند روی یک مک M1 یا یک پردازنده گرافیکی مصرفکننده انویدیا اجرا شود.
همه چیز به قدری سریع پیش می رود که گاهی وقت ها به سختی می توان با آخرین تحولات همراه بود. (در رابطه با سرعت پیشرفت هوش مصنوعی، یکی از خبرنگاران هوش مصنوعی به Ars گفت: “مثل آن ویدیوهایی از سگ هاست که در آن جعبه ای از توپ های تنیس را روی آنها می اندازید. [They] نمی دانم کجا را اول تعقیب کنم و در سردرگمی گم شوم.”)
به عنوان مثال، در اینجا لیستی از رویدادهای قابل توجه مرتبط با LLaMA بر اساس جدول زمانی ارائه شده توسط ویلیسون در نظر هکر نیوز آمده است:
- 24 فوریه 2023: هوش مصنوعی متا LLaMA را اعلام کرد.
- 2 مارس 2023: شخصی مدل های LLaMA را از طریق BitTorrent افشا می کند.
- 10 مارس 2023: گئورگی گرگانوف llama.cpp را ایجاد می کند که می تواند روی M1 Mac اجرا شود.
- 11 مارس 2023: آرتم آندرینکو LLaMA 7B را اجرا می کند (به آرامی) روی Raspberry Pi 44 گیگابایت رم, 10 ثانیه / توکن.
- 12 مارس 2023: LLaMA 7B در NPX، یک ابزار اجرای node.js اجرا میشود.
- 13 مارس 2023: شخصی llama.cpp را اجرا می کند در گوشی پیکسل 6، همچنین بسیار کند.
- 13 مارس 2023: استنفورد Alpaca 7B را منتشر کرد، یک نسخه تنظیمشده با دستورالعمل از LLaMA 7B که رفتاری مشابه با «text-davinci-003» OpenAI دارد، اما روی سختافزار بسیار ضعیفتر اجرا میشود.
پس از به دست آوردن وزنه های LLaMA، دستورالعمل های ویلیسون را دنبال کردیم و نسخه پارامتر 7B را بر روی M1 Macbook Air اجرا کردیم و با سرعت معقولی کار می کند. شما آن را به عنوان یک اسکریپت در خط فرمان با یک اعلان فراخوانی می کنید، و LLaMA تمام تلاش خود را می کند تا آن را به روشی معقول تکمیل کند.
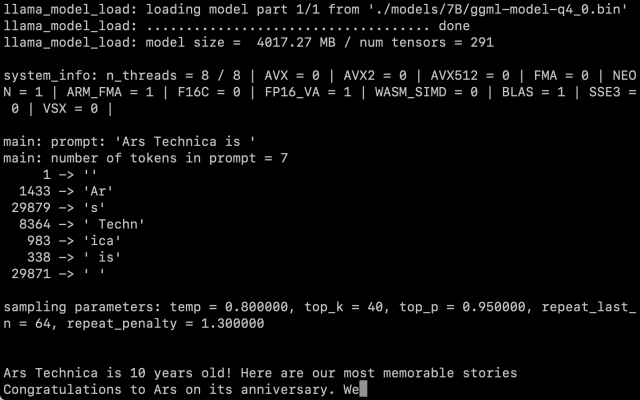
بنج ادواردز / Ars Technica
هنوز این سوال وجود دارد که میزان کمیت چقدر بر کیفیت خروجی تأثیر می گذارد. در آزمایشهای ما، LLaMA 7B کاهشیافته به کوانتیزهسازی 4 بیتی برای اجرا بر روی مکبوک ایر بسیار چشمگیر بود – اما هنوز هم با آنچه از ChatGPT انتظار دارید، نبود. این کاملاً ممکن است که تکنیکهای تحریک بهتر نتایج بهتری ایجاد کنند.
همچنین، بهینهسازیها و تنظیمات دقیق زمانی به سرعت انجام میشوند که همه دستشان روی کد و وزنها باشد – حتی اگر LLaMA هنوز با برخی شرایط استفاده نسبتاً محدودکننده همراه است. انتشار امروز Alpaca توسط استنفورد ثابت می کند که تنظیم دقیق (آموزش اضافی با هدفی خاص) می تواند عملکرد را بهبود بخشد، و هنوز روزهای اولیه پس از انتشار LLaMA باقی مانده است.
از زمان نگارش این مقاله، اجرای LLaMA در مک یک تمرین نسبتاً فنی باقی مانده است. شما باید پایتون و Xcode را نصب کنید و با کار بر روی خط فرمان آشنا باشید. ویلیسون دستورالعمل های گام به گام خوبی برای هر کسی که مایل به انجام آن است دارد. اما این ممکن است به زودی تغییر کند زیرا توسعه دهندگان همچنان به کدنویسی ادامه می دهند.
در مورد پیامدهای عرضه این فناوری در طبیعت – هنوز کسی نمی داند. در حالی که برخی نگران تأثیر هوش مصنوعی به عنوان ابزاری برای هرزنامه و اطلاعات نادرست هستند، ویلیسون میگوید: “این اختراع نخواهد بود، بنابراین فکر میکنم اولویت ما باید کشف سازندهترین راههای ممکن برای استفاده از آن باشد.”
در حال حاضر، تنها تضمین ما این است که همه چیز به سرعت تغییر خواهد کرد.







{kind=link}