

ChatGPT قرار است موجی از راههای کاربرپسند جدید را برای کار با پایگاههای داده سازمانی راهاندازی کند.
یکی از اولین مواردی که از دروازه خارج شد، پایگاه داده تحلیلی بردار Kinetica است. ادغام Kinetica با ChatGPT به کاربران امکان می دهد سوالات زبان طبیعی بپرسند – و نیاز به دانستن SQL (زبان پرس و جو ساختاریافته) را نادیده بگیرند. Kinetica این رابط کاربر پسند سطح بعدی را “پرس و جوی مکالمه” می نامد.
فیل دارینگر، معاون مدیریت محصول Kinetica به IDN گفت: «با «پرس و جوی مکالمه»، ChatGPT سؤال و هدف کاربر را درک می کند و ورودی زبان طبیعی را به سؤالات SQL رسمی که پایگاه داده می فهمد، ترجمه می کند. او افزود، علاوه بر این، «پرس و جوی مکالمه» «به کاربران اجازه میدهد با استفاده از کلمات و عبارات خود سؤال بپرسند».
شاید حتی قوی تر، Darringer گفت ChatGPT به کاربران اجازه می دهد مکالمه طولانی مدت و تعاملی با داده های خود داشته باشند. او گفت که پس از سؤال یا پرس و جو اولیه خود، کاربران می توانند با سؤالات بعدی «به اصلاح سؤالات خود ادامه دهند» تا نتایج دقیق تر و دقیق تر به دست آورند.
دارینگر گفت: «ما فکر میکنیم که کل این ایده «پرس و جوی مکالمه» با ChatGPT دری را فراتر از کسانی که در SQL مهارت دارند به روی هر نوع کاربر تجاری که میتواند انواع سؤالات را بهعنوان درخواستهای زبان طبیعی قاب کند باز کند.
![]()
دارینگر گفت، فراتر از سهولت استفاده برای کاربران غیر فنی، «پرس و جوهای مکالمه» مزایای دیگری نیز ارائه می دهد، از جمله:
- افزایش بهره وری: با فراهم کردن دسترسی بلادرنگ به اطلاعات، کاربران پاسخ فوری به سؤالات خود را دریافت می کنند – بدون انتظار برای ایجاد پرس و جوهای طولانی مدت یا خطوط لوله داده. این باعث صرفه جویی در زمان و بهبود کارایی کلی می شود.
- بینش دادههای بهبود یافته: با امکان پرسیدن یک سری سؤالات تکراری، کاربران میتوانند الگوهای جدید یا همبستگیها و روابط غیرمنتظرهای را که ممکن است بلافاصله از طریق پرسوجوهای سنتی آشکار نشده باشند، کشف کنند.
بخش عمده ای از جادوی راه حل ChatGPT/Kinetica از ادغام خوب طراحی شده این دو فناوری ناشی می شود:
ChatGPT دارینگر به IDN گفت که دارای قابلیت های ذاتی قوی برای تبدیل زبان طبیعی به SQL خوب است و در ادامه به برخی موارد قابل توجه اشاره کرد.
«ChatGPT بر روی دادههای اینترنتی آموزش دیده است، میتواند به خوبی کد بنویسد و SQL را به خوبی میشناسد و عملیات اتصال SQL را میداند، و این نتایج بسیار خوبی را ارائه کرده است. [with Kinetica] در حال حاضر، “او گفت. او افزود که گفته شد، ChatGPT همچنین باید از برخی ویژگیهای مربوط به دادههای کاربر، مانند نامها و تعاریف ستونها و نوع دادهها و غیره آگاه باشد. اما این یک مانع بزرگ برای ChatGPT نیست. “در حقیقت [ChatGPT] فقط با ارائه DDL برای جداول بسیار خوب عمل می کند.”
با این حال، در موارد خاص، دارینگر خاطرنشان کرد: «ChatGPT به نکاتی در مورد نحوه کارکرد خوب با Kinetica نیاز دارد. بنابراین ما می توانیم [let users easily] ابرداده و زمینه اختیاری را برای ChatGPT ارائه دهید و به آن بگویید که چگونه SQL را به روشی بیان کند که برای Kinetica بهترین کار را انجام دهد.
در مورد کینتیکادارینگر به IDN گفت، پایگاه داده برداری شده با کارایی بالا، پاسخی سریع به پرس و جوهای محاوره ای را فراهم می کند و به کاربران «تحلیل داده های موقتی واقعی با سرعت» را ارائه می دهد.
یک جنبه کلیدی از پاسخ سریع پایگاه داده Kinetica از استفاده شرکت از “بردارسازی بومی” ناشی می شود.
در یک موتور پرس و جو بردار، داده ها در بلوک های با اندازه ثابت (به نام بردار) ذخیره می شوند. عملیات پرس و جو بر روی این بردارها به صورت موازی انجام می شود – نه بر روی عناصر داده منفرد. این رویکرد به موتور پرس و جو اجازه می دهد تا چندین عنصر داده را به طور همزمان پردازش کند، که نتایج جستجوی سریع تری را با محاسبه کمتر ارائه می دهد. بردارسازی Kinetica برای پیشرفتهای GPU و CPU بهینه شده است، که به پایگاه داده اجازه میدهد تا محاسبات همزمان را روی عناصر دادهای متعدد انجام دهد و آنها را به صورت موازی در چندین هسته یا رشته پردازش کند.
دارینگر به IDN گفت: یکی دیگر از ویژگی های برجسته ازدواج ChatGPT/Kinetica، توانایی راه حل برای ارائه پاسخ سریع به سؤالات غیرمنتظره یا «سوالاتی که قبلاً دیده نشده» است.
دارینگر به IDN گفت: «اگر من تخمین زده باشم، احتمالاً 80 تا 90 درصد از سؤالات SQL از قبل شناخته شده است. “آنها در برابر یک طرح واره به خوبی تعریف شده با خط لوله داده به خوبی تعریف شده، یک فرهنگ لغت داده به خوبی تعریف شده و همه تبدیل داده ها همه قفل شده اند، تعریف شده اند. بنابراین، اکثر پرس و جوها همگی از قبل برنامه ریزی شده اند.”
دارینگر اضافه کرد که به این دلیل است که پرسیدن چنین سؤالی «قبلاً دیده نشده» (یا برنامه ریزی نشده) مشکلات فنی واقعی را ایجاد می کند.
دارینگر به IDN گفت: «این گونه سؤالات «تا به حال دیده نشده» ممکن است ساعت ها طول بکشد – یا اصلاً کامل نشوند. به این دلیل که مهندسان داده باید مطمئن شوند که پایگاه داده برای آنها آماده است. «شما باید بدانید که آیا دادهها حتی وجود دارند یا خیر، و آیا آنها طوری تنظیم شدهاند که در برابر آن پرس و جو عملکرد خوبی داشته باشند. حتی بعد از همه اینها، باید بدانید:
آیا باید خط لوله داده خود را دوباره مهندسی کنم؟ آیا شاخصهای من از آن نوع سؤال جدیدی که قبلاً ندیدهام پشتیبانی میکند؟»
پایگاه داده کینتیکا به گونه ای طراحی شده است که برای چنین سوالات پیش بینی نشده ای آماده باشد. دررینگر گفت، بدون هیچ گونه پیش مهندسی، کینتیکا می تواند هر سوالی را که به آن مطرح می شود رسیدگی کند و پاسخ ها را در چند ثانیه ارسال کند.
ما بدون شاخص ها به خوبی کار می کنیم و نیازی به مهندسی داده نداریم. این انعطافپذیری به کاربران اجازه میدهد تا طیف گستردهای از سؤالات را بپرسند، حتی سؤالاتی که قبلاً دیده نشدهاند – بدون نیاز به مهندسان داده برای انجام کارهای راهاندازی زیادی.»
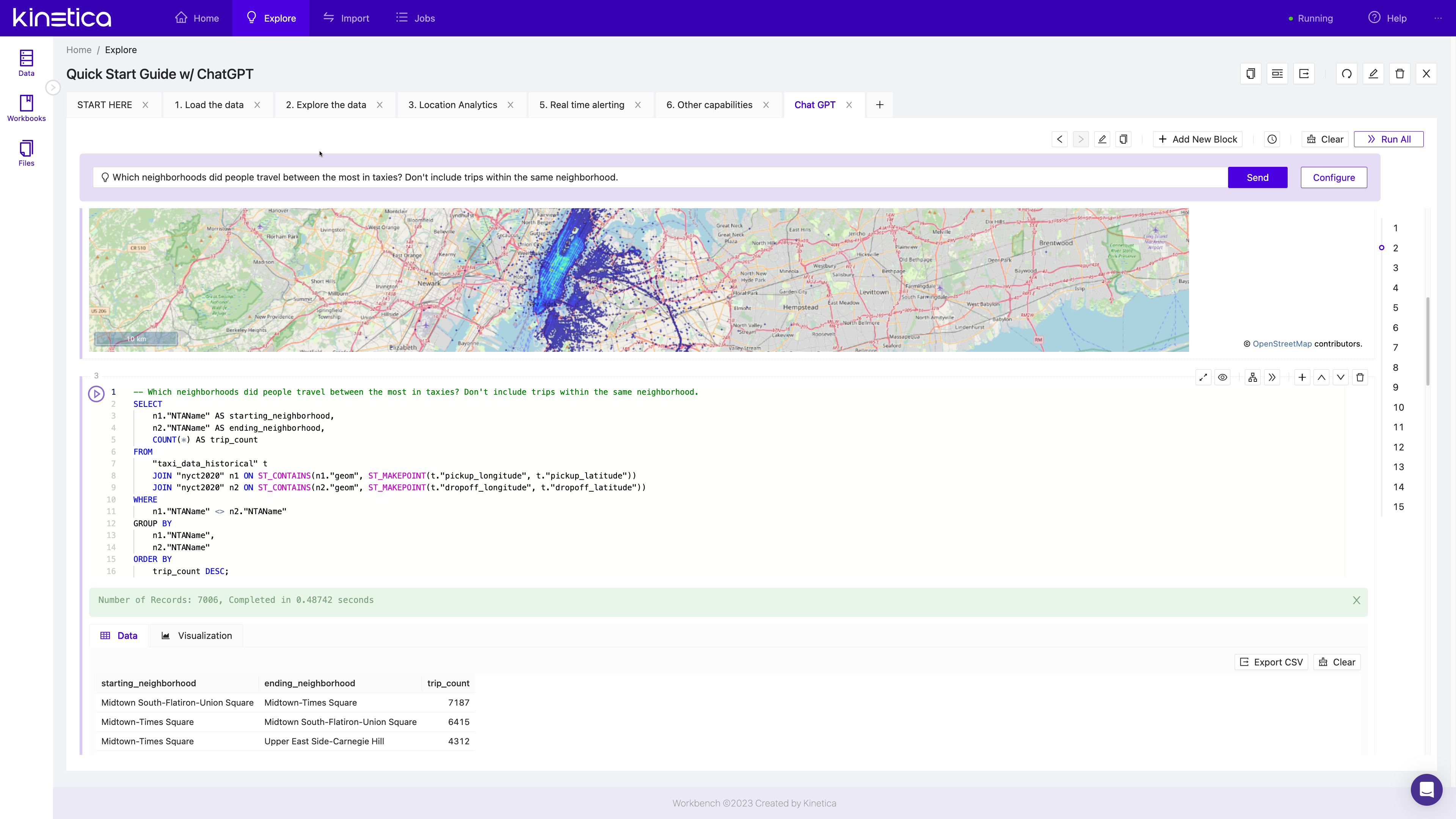
Darringer اضافه کرد که معماری آماده برای هر سوالی Kinetica به مزایای ادغام ChatGPT/Kinetica کمک می کند. اگر ChatGPT میتواند SQL عالی ایجاد کند، اما نمیدانید که آیا برای یک نوع پرس و جو تنظیم شدهاید، نگران نباشید. نتیجه را در بازه زمانی که انتظار دارید برمی گردانید [from Kinetica] وقتی با ChatGPT مکالمه می کنید.
سایر مزایای ادغام Kinetica/Chat GPT:
دارینگر مزایای دیگری را از ادغام ChatGPT/Kinetica به اشتراک گذاشته است، از جمله:
پردازش داده ها در زمان واقعی: کاربران را قادر می سازد تا داده ها را در زمان واقعی تجزیه و تحلیل و پاسخ دهند. این بینش ها و اقدامات فوری را بر اساس داده هایی که از طریق سیستم جریان می یابد، ارائه می دهد.
مقیاس پذیری و عملکرد: قابلیتهای پردازش موازی و توزیعشده Kinetica ChatGPT را قادر میسازد تا حجم زیادی از دادهها و تعاملات همزمان کاربر را با کارایی و سرعت بالا مدیریت کند. این امکان مقیاسپذیری یکپارچه را فراهم میکند و تضمین میکند که ChatGPT میتواند با افزایش حجم کار همگام شود.
تجزیه و تحلیل پیشرفته: Kinetica دارای قابلیتهای تحلیلی پیشرفته داخلی است، از جمله یادگیری ماشین، پردازش جغرافیایی و تجزیه و تحلیل سریهای زمانی. این دقت پاسخهای ChatGPT را افزایش میدهد و تجربه کاربری شخصیسازیشدهتری را ارائه میدهد.
یکی دیگر از ابعاد انعطاف پذیری در پرس و جوها قابل ذکر است این است که چگونه ادغام ChatGPT/Kinetica به کاربران اجازه می دهد تا برای پاسخ های خود از منابع داده دیگر استفاده کنند.
دارینگر گفت که معماری پایگاه داده برداری شده Kinetica برای ترکیب پایگاه های داده و تکنیک های تجزیه و تحلیل متعدد ساخته شده است.
کاربران Kinetica با استفاده از یک فرانتاند ChatGPT، یک کوئری پایگاه داده رابطهای را گسترش میدهند تا دادههایی را از موارد زیر (در هر ترکیبی) اضافه کنند:
- تجزیه و تحلیل نمودار (برای کشف روابط بین نقاط داده)،
- تجزیه و تحلیل اصطلاحی (برای تجزیه و تحلیل داده ها در طول زمان)،
- تحلیل فضایی (برای درک الگوهای جغرافیایی) و
- یادگیری ماشین (برای ارائه بینش عمیق تر از داده ها)
دارینگر نمونه ای از نحوه کارکرد این کار را به اشتراک گذاشت. دارینگر گفت: «میتوانید آن را بهعنوان یک جدول خارجی تعریفشده در Kinetica تنظیم کنید، اما پس از انجام این کار، میتوانید پرسوجوهایی بنویسید – یا ChatGPT به شما کمک میکند تا کوئریها را بنویسید – که به دادههای ساکن در Kinetica میپیوندند».
زمانی که کاربران می توانند با استفاده از زبان طبیعی با داده های خود وارد مکالمات شوند، ما فکر می کنیم که این نوع سوالات به طور طبیعی به قابلیت های نمودار خاصی و همچنین داده های زمانی و مکانی نیاز دارند.
برای کسانی که می خواهند ببینند راه حل Kinetica/ChatGPT چگونه کار می کند، Kinetica یک محیط آزمایشی رایگان مبتنی بر SaaS با استفاده از داده های عمومی ارائه می دهد.
جای تعجب نیست که مشتریان در حال حاضر مشتاق یک راه حل پایگاه داده Kinetica/ChatGPT هستند که می تواند روی فرضیه اجرا شود یا با داده های خصوصی شرکت هایشان اجرا شود.







{kind=link}