

تصویر توسط نویسنده
ChatGPT، جانشین آن GPT-4، و جایگزین های منبع باز آنها بسیار موفق بوده اند. توسعه دهندگان و دانشمندان داده همگی به دنبال بهره وری بیشتر هستند و از ChatGPT برای ساده کردن وظایف روزانه خود استفاده می کنند.
در اینجا، نحوه استفاده از ChatGPT برای علم داده را از طریق یک جلسه برنامه نویسی جفت با ChatGPT خواهیم دید. ما یک مدل طبقهبندی متن میسازیم، مجموعه داده را تجسم میکنیم، بهترین پارامترهای فوق را برای مدل شناسایی میکنیم، الگوریتمهای مختلف یادگیری ماشین را امتحان میکنیم و موارد دیگر—همه با استفاده از ChatGPT.
در طول مسیر، ما همچنین به نکات خاصی برای ساختاربندی اعلانها نگاه میکنیم تا نتایج مفیدی دریافت کنیم. برای پیگیری، باید یک حساب OpenAI رایگان داشته باشید. اگر کاربر GPT-4 هستید، میتوانید با همان درخواستها نیز دنبال کنید.
اجازه دهید سعی کنیم یک مدل طبقه بندی اخبار با استفاده از ChatGPT برای مجموعه داده های ۲۰ گروه خبری در scikit-learn بسازیم.
در اینجا دستوری که استفاده کردم این بود: «من می خواهم یک مدل طبقه بندی اخبار با استفاده از مجموعه داده گروه های خبری sklearn 20 بسازم. راجع به این چیزی میدانی؟”
اگرچه درخواست من در این مرحله خیلی خاص نیست، من هم هدف و هم مجموعه داده را بیان کرده ام:
- هدف: ساخت یک مدل طبقه بندی جدید
- مجموعه داده مورد استفاده: مجموعه داده های 20 گروه خبری از scikit-learn
پاسخ ChatGPT به ما می گوید که با بارگیری مجموعه داده شروع کنیم.
# Load the dataset
newsgroups_train = fetch_20newsgroups(subset="train", shuffle=True)
newsgroups_test = fetch_20newsgroups(subset="test", shuffle=True)همانطور که هدف را نیز بیان کردیم (ساخت یک مدل طبقه بندی متن)، ChatGPT به ما می گوید که چگونه می توانیم این کار را انجام دهیم.
می بینیم که مراحل زیر را به ما می دهد:
- استفاده كردن
TfidfVectorizerبرای پیش پردازش متن و ارائه یک نمایش عددی. این رویکرد استفاده از امتیازات TF-IDF بهتر از استفاده از تعداد رخدادها با استفاده از a استCountVectorizer. - ایجاد یک مدل طبقه بندی بر روی نمایش عددی مجموعه داده با استفاده از طبقه بندی کننده ساده بیز یا ماشین بردار پشتیبان (SVM).
همچنین کد یک طبقهبندیکننده چندجملهای Naive Bayes را داده است، بنابراین بیایید از آن استفاده کنیم و بررسی کنیم که آیا میتوانیم یک مدل کارآمد از قبل داشته باشیم.
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.metrics import classification_report
# Preprocess the text data
vectorizer = TfidfVectorizer(stop_words="english")
X_train = vectorizer.fit_transform(newsgroups_train.data)
X_test = vectorizer.transform(newsgroups_test.data)
# Train a Naive Bayes classifier
clf = MultinomialNB()
clf.fit(X_train, newsgroups_train.target)
# Evaluate the performance of the classifier
y_pred = clf.predict(X_test)
print(classification_report(newsgroups_test.target, y_pred))من جلو رفتم و کد بالا را اجرا کردم. و همانطور که انتظار می رود کار می کند – بدون خطا. ما از یک صفحه خالی به یک مدل طبقه بندی متن – در چند دقیقه – با یک اعلان رفتیم.
Output >>
precision recall f1-score support
0 0.80 0.69 0.74 319
1 0.78 0.72 0.75 389
2 0.79 0.72 0.75 394
3 0.68 0.81 0.74 392
4 0.86 0.81 0.84 385
5 0.87 0.78 0.82 395
6 0.87 0.80 0.83 390
7 0.88 0.91 0.90 396
8 0.93 0.96 0.95 398
9 0.91 0.92 0.92 397
10 0.88 0.98 0.93 399
11 0.75 0.96 0.84 396
12 0.84 0.65 0.74 393
13 0.92 0.79 0.85 396
14 0.82 0.94 0.88 394
15 0.62 0.96 0.76 398
16 0.66 0.95 0.78 364
17 0.95 0.94 0.94 376
18 0.94 0.52 0.67 310
19 0.95 0.24 0.38 251
accuracy 0.82 7532
macro avg 0.84 0.80 0.80 7532
weighted avg 0.83 0.82 0.81 7532اگرچه ما یک مدل کار برای حل مشکل در دست داریم، در اینجا نکات خاصی وجود دارد که می تواند در هنگام درخواست به شما کمک کند. درخواست می توانست بهتر باشد و به مراحل کوچکتر تقسیم شود، مانند:
- لطفاً درباره مجموعه دادههای گروههای خبری 20 scikit-learn بیشتر به من بگویید.
- کارهای ممکنی که می توانم با این مجموعه داده انجام دهم چیست؟ آیا می توانم یک مدل طبقه بندی متن بسازم؟
- آیا می توانید به من بگویید که کدام الگوریتم یادگیری ماشین برای این برنامه مناسب تر است؟
خوب، ما قبلاً یک مدل طبقه بندی متن ساخته ایم. اما خیلی سریع اتفاق افتاد، بنابراین بیایید سرعت خود را کم کنیم و سعی کنیم به تجسم ساده مجموعه داده بیاییم.
به طور خاص، بیایید سعی کنیم توزیع نمونه های آموزشی را در بین 20 دسته خبری درک کنیم و تشخیص دهیم که آیا عدم تعادل طبقاتی وجود دارد یا خیر.
در اینجا اعلانی است که من استفاده کردم: “من می خواهم مجموعه داده را برای درک توزیع کلاس و شناسایی عدم تعادل کلاس تجسم کنم. آیا میتوانید در تجسم به من کمک کنید؟»
ChatGPT پیشنهاد کرد که نمودار میله ای یا هیستوگرام تعداد نمونه ها در هر یک از کلاس ها تجسم خوبی خواهد بود. منطقی به نظر می رسد.
در اینجا کدی است که ChatGPT برای ایجاد یک نمودار میله ای ساده در matplotlib ایجاد کرده است:
import matplotlib.pyplot as plt
# Load the dataset
newsgroups_train = fetch_20newsgroups(subset="train", shuffle=True)
# Count the number of samples for each class
class_counts = {}
for label in newsgroups_train.target:
class_name = newsgroups_train.target_names[label]
if class_name in class_counts:
class_counts[class_name] += 1
else:
class_counts[class_name] = 1
# Plot the class distribution
plt.bar(class_counts.keys(), class_counts.values())
plt.xticks(rotation=90)
plt.xlabel('Class')
plt.ylabel('Number of Samples')
plt.title('Class Distribution')
plt.show()در اینجا طرح است. تمیز است، برچسب ها قابل خواندن هستند. همچنین می توانیم تعداد نمونه ها را در هر 20 کلاس مشاهده کنیم.
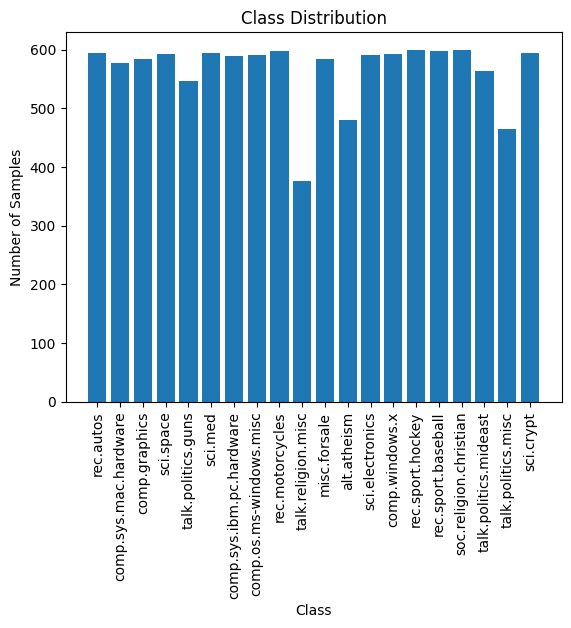
توزیع نمونه های آموزشی در بین 20 کلاس تقریباً یکنواخت است و عدم تعادل کلاسی قابل مشاهده نیست. بنابراین مدلی که در مرحله قبل به دست آوردیم مفید است. و ما نیازی به استفاده از تکنیکهای جدید نمونهگیری برای رسیدگی به عدم تعادل طبقاتی نداریم.
در مرحله بعد، من می خواهم ابرپارامترهای مدل را تنظیم کنم. ابتدا، من مایلم فراپارامترهای مختلفی را که می توان تنظیم کرد، درک کنم. سپس، اگر فراپارامترهای زیادی وجود نداشته باشد، می توانیم یک جستجوی شبکه ای ساده انجام دهیم.
این اعلان است: “آیا فراپارامترهایی وجود دارد که بتوانم برای بهتر کردن مدل طبقه بندی کننده تنظیم کنم؟”
در کدی که گرفتیم، max_df برای TfidfVectorizer همچنین قابل تنظیم است. ما می دانیم که امتیاز TF-IDF با تخصیص وزن بالاتر به عباراتی که اغلب در یک سند خاص اتفاق می افتد کار می کند در حالی که وزن بسیار کمتری را به عباراتی که اغلب در همه اسناد وجود دارد اختصاص می دهد. این max_df از درصد وقوع برای نادیده گرفتن یک عبارت خاص استفاده می کند.
مثلا، max_df 0.5 نشان می دهد که تمام عباراتی که در حداقل 50٪ اسناد وجود دارد نادیده گرفته می شود. اگر مایلید، می توانید این را حذف کنید. اما من می خواهم آن را حفظ کنم تا ببینم چیست max_df من میتوانم استفاده کنم.
کد از یک جستجوی شبکه ای ساده استفاده می کند و مقادیر بهینه را بر اساس امتیازهای اعتبارسنجی متقابل انتخاب می کند.
from sklearn.model_selection import GridSearchCV
from sklearn.pipeline import Pipeline
# Define the pipeline with TF-IDF and Multinomial Naive Bayes
pipeline = Pipeline([
('tfidf', TfidfVectorizer(stop_words="english")),
('clf', MultinomialNB())
])
# Define the hyperparameter grid
param_grid = {
'tfidf__max_df': [0.5, 0.75, 1.0],
'clf__alpha': [0.1, 0.5, 1.0],
'clf__fit_prior': [True, False],
}
# Perform grid search with cross-validation
grid_search = GridSearchCV(pipeline, param_grid, cv=5)
grid_search.fit(newsgroups_train.data, newsgroups_train.target)
# Print the best hyperparameters and cross-validation score
print("Best hyperparameters: ", grid_search.best_params_)
print("Cross-validation score: ", grid_search.best_score_)Output >>
Best hyperparameters: {'clf__alpha': 0.1, 'clf__fit_prior': False, 'tfidf__max_df': 0.5}
Cross-validation score: 0.9088736147919108با وصل کردن مقادیر این هایپرپارامترها، حدود 2 درصد در دقت طبقه بندی بهبود پیدا کردم.
در اینجا، ما پارامترهای زیادی برای تنظیم نداشتیم. اگر فراپارامترهای زیادی دارید که هر کدام می توانند مجموعه ای از مقادیر را دریافت کنند، اجرای جستجوی شبکه ممکن است گران باشد. و ممکن است منطقی باشد که به جای آن یک جستجوی تصادفی انجام دهید.
ما در یکی از اولین مراحل دیدیم که یک SVM برای چنین مشکل طبقه بندی نیز به خوبی کار می کند.
اکنون میخواهم یک طبقهبندی بردار پشتیبانی برای همان مجموعه داده بسازم.
درخواستی که استفاده کردم: «آیا میتوانید به من اطلاع دهید که آیا میتوانم از SVM برای حل همان مشکل استفاده کنم؟ آیا می توانید کدی را برای این کار ایجاد کنید؟”
و در اینجا می رویم:
from sklearn.datasets import fetch_20newsgroups
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
# Load the dataset
newsgroups_train = fetch_20newsgroups(subset="train", shuffle=True)
# Convert the text data to a matrix of TF-IDF features
vectorizer = TfidfVectorizer()
X = vectorizer.fit_transform(newsgroups_train.data)
y = newsgroups_train.target
# Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Define the SVM classifier
clf = SVC(kernel="linear")
# Train the SVM classifier
clf.fit(X_train, y_train)
# Predict the class labels for the test set
y_pred = clf.predict(X_test)
# Calculate the accuracy of the SVM classifier
accuracy = accuracy_score(y_test, y_pred)
print('Accuracy:', accuracy)با توجه به اینکه ما امتیاز دقت بالای 90% داریم، به نظر می رسد SVM انتخاب خوبی برای این مجموعه داده باشد.
Output >> Accuracy: 0.9019001325673884همانطور که مشاهده شد، می توانید از ChatGPT برای آزمایش سریع مدل های مختلف برای حل یک مشکل استفاده کنید.
هنگامی که ساخت یک مدل کار را دوچندان کردید، می توانید سایر مسیرهای موجود را نیز بررسی کنید. بیایید به عنوان مثال به کاهش ابعاد نگاه کنیم.
در این مرحله، من علاقه ای به اجرای الگوریتم های کاهش ابعاد ندارم زیرا از قبل یک مدل کار دارم. و فضای ویژگی ابعاد چندان بالایی ندارد. بنابراین ما نیازی به کاهش تعداد ابعاد قبل از ساخت مدل نداریم.
با این حال، بیایید به رویکردهای کاهش ابعاد برای این مجموعه داده خاص نگاه کنیم.
درخواستی که استفاده کردم: “آیا می توانید تکنیک های کاهش ابعاد را که می توانم برای این مجموعه داده استفاده کنم به من بگویید؟”

تکنیک های زیر توسط ChatGPT پیشنهاد شده است:
- تحلیل معنایی پنهان یا SVD
- تجزیه و تحلیل اجزای اصلی (PCA)
- فاکتورسازی ماتریس غیر منفی (NMF)
بیایید بحث خود را با برشمردن بهترین شیوه های استفاده از ChatGPT به پایان برسانیم.
موارد زیر برخی از بهترین شیوه هایی است که باید هنگام استفاده از ChatGPT برای علم داده به خاطر داشت:
- داده های حساس و کد منبع را وارد نکنید: هیچ داده حساسی را به ChatGPT وارد نکنید. وقتی روی تیمهای داده در سازمانها کار میکنید، اغلب مدلهایی را بر روی دادههای مشتری میسازید – که باید محرمانه بماند. در عوض میتوانید نمونههای اولیه را برای مجموعه دادههای در دسترس عمومی مشابه بسازید و سعی کنید آن را به مجموعه داده یا مشکل خود منتقل کنید. به همین ترتیب، از وارد کردن کد منبع حساس یا هرگونه اطلاعاتی که نباید فاش شود، خودداری کنید.
- با درخواست های خود مشخص باشید: بدون درخواست های خاص، دریافت پاسخ های مفید از ChatGPT بسیار دشوار است. بنابراین، دستور خود را طوری ساختار دهید که به اندازه کافی خاص باشند. اعلان ها حداقل باید هدف را به وضوح بیان کنند. هر بار یک قدم.
- اعلان های طولانی تر را به اعلان های کوچکتر تجزیه کنید: اگر یک زنجیره فکری برای انجام یک کار خاص دارید، سعی کنید آن را به مراحل سادهتر تقسیم کنید و از ChatGPT بخواهید هر یک از مراحل را انجام دهد.
- اشکال زدایی موثر با استفاده از ChatGPT: در این مثال تمام کدهایی که دریافت کردیم بدون خطا اجرا شد. اما ممکن است همیشه اینطور نباشد. ممکن است به دلیل ویژگیهای منسوخ، مراجع API نامعتبر و موارد دیگر با خطا مواجه شوید. هنگامی که با خطا مواجه می شوید، می توانید پیام خطا و ردیابی مربوطه را در درخواست خود وارد کنید. و به راه حل های ارائه شده نگاه کنید، سپس اقدام به دیباگ کد خود کنید.
- پیامها را پیگیری کنید: اگر از ChatGPT زیاد استفاده می کنید (یا قصد استفاده از آن را دارید) در گردش کار روزانه علم داده خود، ممکن است ایده خوبی باشد که اعلان ها را پیگیری کنید. این می تواند به اصلاح درخواست ها در طول زمان و شناسایی تکنیک های مهندسی سریع برای دریافت نتایج بهتر از ChatGPT کمک کند.
هنگام استفاده از ChatGPT برای برنامه های کاربردی علم داده، درک مشکل کسب و کار اولین و مهمترین مرحله است. بنابراین، ChatGPT تنها ابزاری برای ساده سازی و خودکارسازی وظایف خاص است و می باشد نه جایگزینی برای تخصص فنی توسعه دهندگان.
با این حال، هنوز هم ابزاری ارزشمند برای افزایش بهرهوری با کمک به ساخت سریع و آزمایش مدلها و الگوریتمهای مختلف است. پس بیایید از ChatGPT استفاده کنیم تا مهارت های خود را تقویت کنیم و توسعه دهندگان بهتری شویم!
بالا پریا سی یک توسعه دهنده و نویسنده فنی از هند است. او دوست دارد در تقاطع ریاضی، برنامه نویسی، علم داده و تولید محتوا کار کند. زمینه های مورد علاقه و تخصص او شامل DevOps، علم داده و پردازش زبان طبیعی است. او از خواندن، نوشتن، کدنویسی و قهوه لذت می برد! در حال حاضر، او در حال کار بر روی یادگیری و به اشتراک گذاری دانش خود با جامعه توسعه دهندگان با نوشتن آموزش ها، راهنماهای نحوه انجام، نظرات و موارد دیگر است.
 درباره NDA ها چت کنیم | روابط عمومی")






{kind=link}