

مطابق با مقایسه قبلی ما بین Gemini 1.5 Pro و GPT-4، ما با یک تست مدل هوش مصنوعی جدید با تمرکز بر مدل Claude 3 Opus Anthropic بازگشته ایم. این شرکت بیان می کند که Claude 3 Opus در نهایت مدل GPT-4 OpenAI را در معیارهای محبوب شکست داده است. برای آزمایش ادعاها، مقایسه دقیقی بین Claude 3 Opus، GPT-4 و Gemini 1.5 Pro انجام داده ایم.
اگر میخواهید بدانید که مدل Claude 3 Opus در استدلال پیشرفته، ریاضیات، دادههای زمینه طولانی، تجزیه و تحلیل تصویر و غیره چگونه عمل میکند، مقایسه ما را در زیر دنبال کنید.
1. تست اپل
I have 3 apples today, yesterday I ate an apple. How many apples do I have now?
بیایید با تست محبوب اپل شروع کنیم که توانایی استدلال LLM ها را ارزیابی می کند. در این تست مدل Claude 3 Opus درست جواب می دهد و می گوید الان سه سیب دارید. با این حال، برای دریافت پاسخ صحیح، مجبور شدم یک اعلان سیستم تنظیم کنم و اضافه کنم که شما یک دستیار باهوش هستید که در استدلال پیشرفته متخصص هستید.
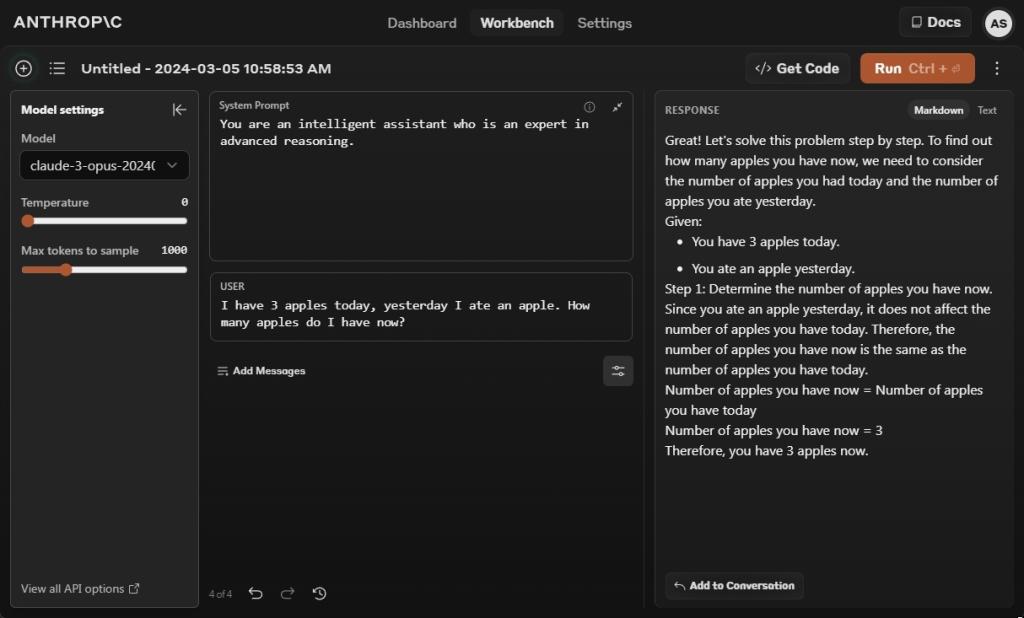
بدون اعلان سیستم، مدل Opus پاسخ اشتباهی می داد. و خوب، Gemini 1.5 Pro و GPT-4 مطابق با تست های قبلی ما پاسخ های صحیحی دادند.
برنده: Claude 3 Opus، Gemini 1.5 Pro و GPT-4
2. زمان را محاسبه کنید
If it takes 1 hour to dry 15 towels under the Sun, how long will it take to dry 20 towels?
در این تست، ما سعی میکنیم مدلهای هوش مصنوعی را فریب دهیم تا ببینیم آیا نشانهای از هوش از خود نشان میدهند یا خیر. و متأسفانه، Claude 3 Opus مانند Gemini 1.5 Pro در این تست مردود شد. من همچنین در اعلان سیستم اضافه کردم که سؤالات می توانند دشوار باشند، بنابراین هوشمندانه فکر کنید. با این حال، مدل Opus در ریاضیات عمیق شد و به یک نتیجه اشتباه رسید.

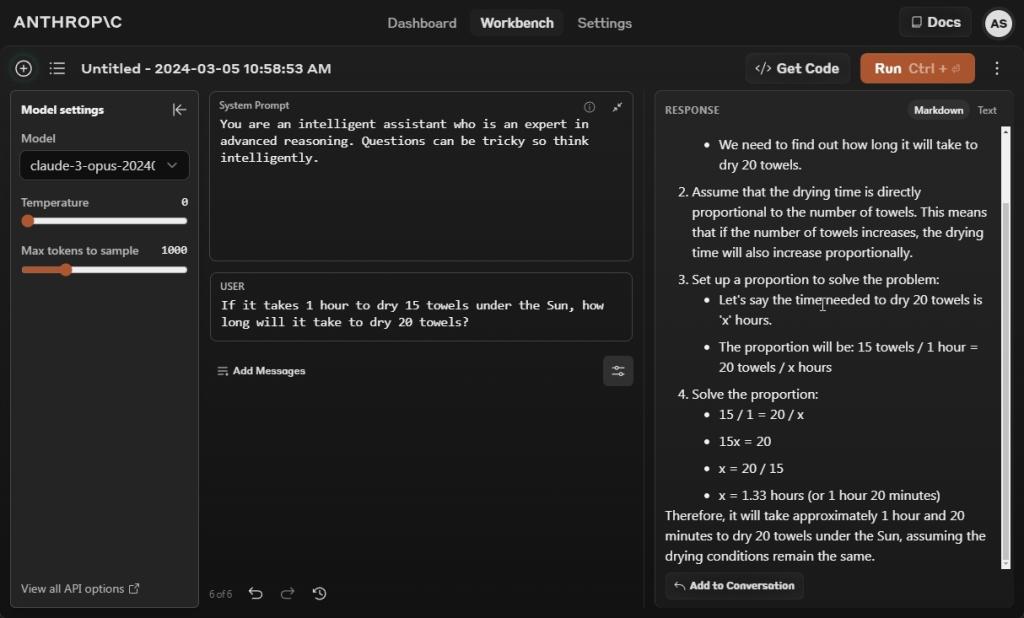
در مقایسه قبلی ما، GPT-4 نیز در این تست پاسخ اشتباهی داده است. با این حال، پس از انتشار نتایج ما، GPT-4 به طور متغیر خروجی تولید می کند، اغلب اشتباه، و گاهی اوقات درست است. امروز صبح دوباره همان فرمان را اجرا کردیم، و GPT-4 یک خروجی اشتباه داد، حتی زمانی که گفته شد از مفسر کد استفاده نکنید.
برنده: هیچ یک
3. وزن را ارزیابی کنید
What's heavier, a kilo of feathers or a pound of steel?
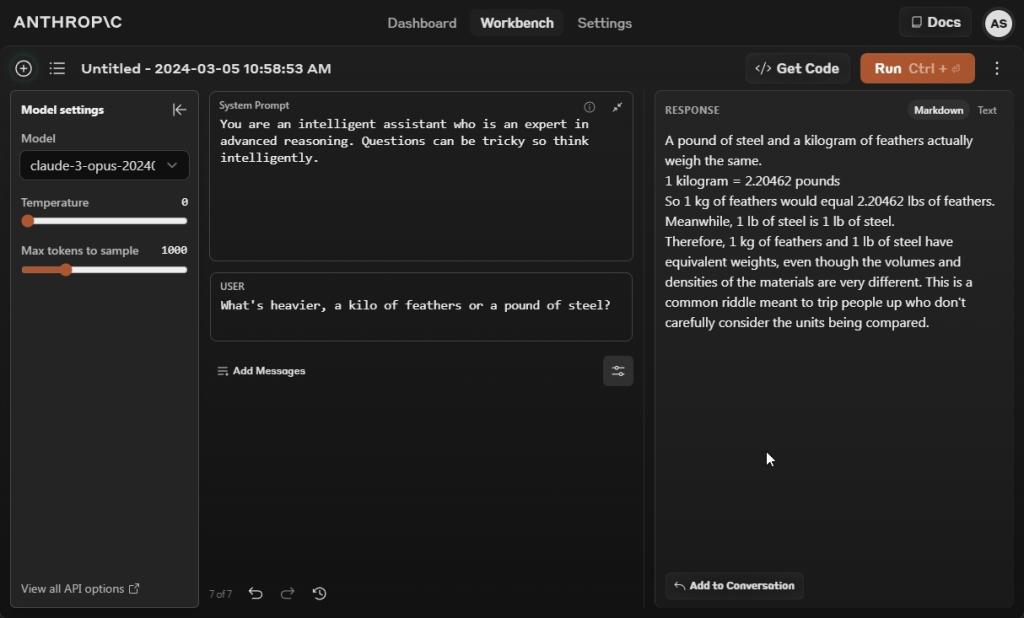
در مرحله بعد، از هر سه مدل هوش مصنوعی پرسیدیم که آیا یک کیلو پر از یک پوند فولاد سنگینتر است یا خیر. و خب، کلود 3 اوپوس جواب اشتباهی داد و گفت که وزن یک پوند فولاد و یک کیلوگرم پر یکسان است.
مدلهای هوش مصنوعی Gemini 1.5 Pro و GPT-4 با پاسخهای صحیح پاسخ دادند. یک کیلو از هر ماده ای از یک پوند فولاد سنگین تر است زیرا ارزش جرمی یک کیلو حدود 2.2 برابر سنگین تر از یک پوند است.
برنده: Gemini 1.5 Pro و GPT-4
4. حل یک مسئله ریاضی
If x and y are the tens digit and the units digit, respectively, of the product 725,278 * 67,066, what is the value of x + y. Can you explain the easiest solution without calculating the whole number?
در سوال بعدی ما از مدل کلود 3 اپوس خواستیم که یک مسئله ریاضی را بدون محاسبه عدد کامل حل کند. و دوباره شکست خورد. هر بار که فرمان را اجرا می کردم، با یا بدون اعلان سیستم، در درجات مختلف پاسخ های اشتباه می داد.
برای دیدن هیجان زده شدم امتیاز 60.1% کلود 3 Opus در معیار ریاضی، بالاتر از GPT-4 (52.9٪) و Gemini 1.0 Ultra (53.2٪).
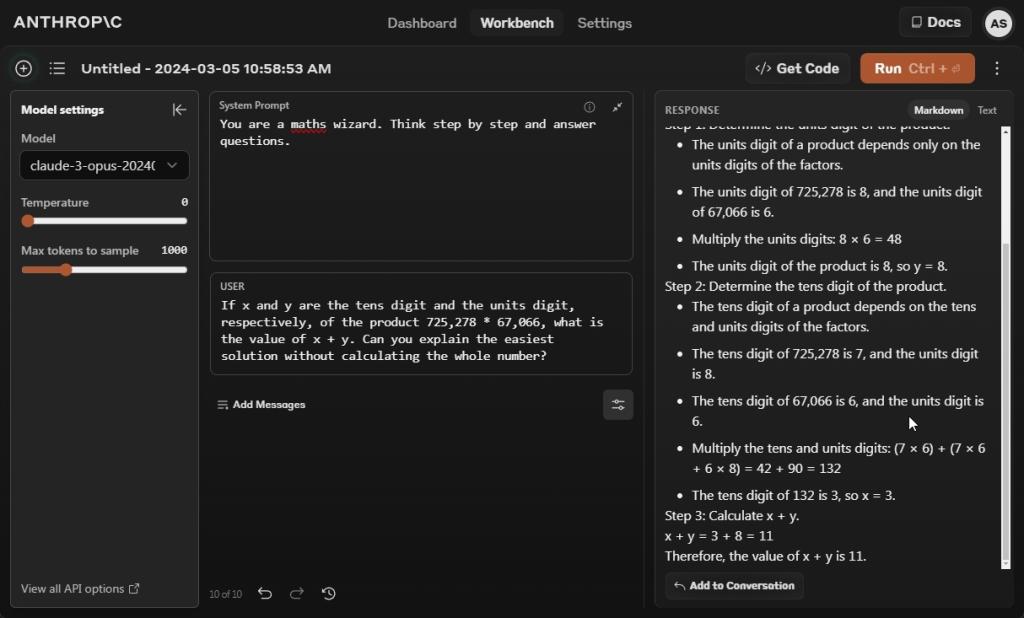
به نظر میرسد با تلقین زنجیرهای از فکر، میتوانید نتایج بهتری از مدل Claude 3 Opus دریافت کنید. در حال حاضر، با درخواست صفر شات، GPT-4 و Gemini 1.5 Pro پاسخ درستی دادند.
برنده: Gemini 1.5 Pro و GPT-4
5. دستورالعمل های کاربر را دنبال کنید
Generate 10 sentences that end with the word "apple"
وقتی صحبت از پیروی از دستورالعمل های کاربر می شود، مدل Claude 3 Opus عملکرد قابل توجهی دارد. این به طور موثر تمام مدلهای هوش مصنوعی را از سلطنت خلع کرده است. هنگامی که از شما خواسته می شود 10 جمله که با کلمه “سیب” ختم می شود، ایجاد کند، 10 جمله کاملا منطقی با کلمه “سیب” ختم می شود.

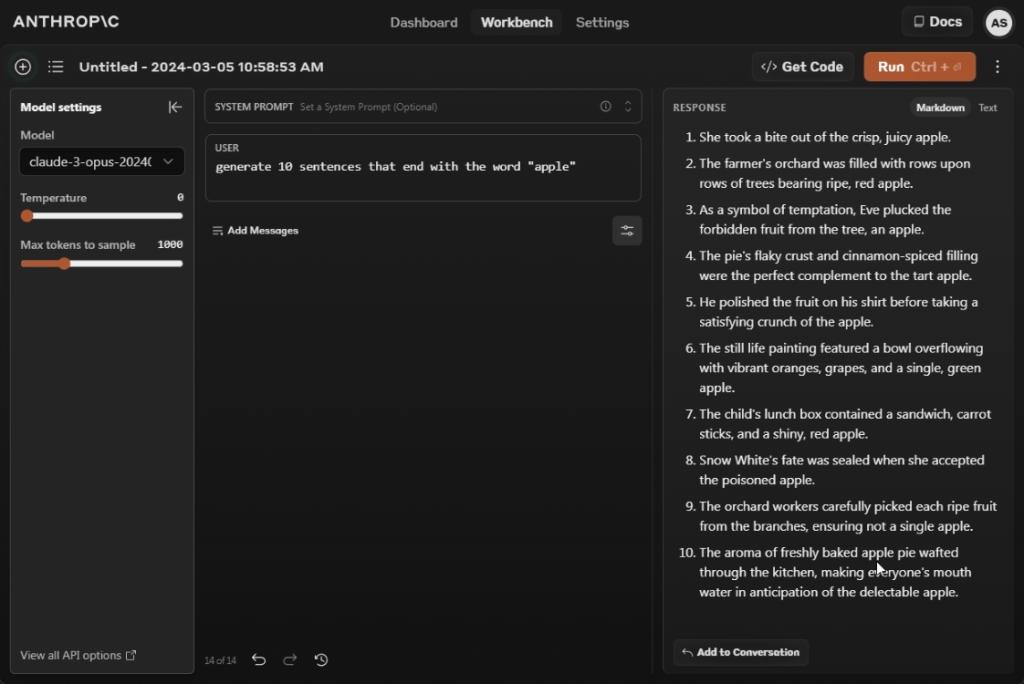
در مقایسه، GPT-4 9 جمله از این قبیل را تولید می کند و Gemini 1.5 Pro بدترین عملکرد را دارد و حتی سه جمله از این قبیل را تولید نمی کند. من می گویم اگر به دنبال یک مدل هوش مصنوعی هستید که در آن پیروی از دستورالعمل های کاربر برای کار شما بسیار مهم است، Claude 3 Opus یک گزینه قوی است.
ما این را در عمل دیدیم که یک کاربر X از Claude 3 Opus خواست تا چندین دستورالعمل پیچیده را دنبال کند و فصلی از کتاب در مورد ویدیوی Tokenizer آندری کارپاتی ایجاد کند. مدل Opus یک کار عالی بود و یک فصل کتاب زیبا ایجاد کرد همراه با دستورالعمل ها، مثال ها و تصاویر مرتبط.
برنده: Claude 3 Opus
6. تست سوزن در انبار کاه (NIAH).
آنتروپیک یکی از شرکت هایی بوده است که مدل های هوش مصنوعی را برای پشتیبانی از یک پنجره زمینه بزرگ تحت فشار قرار داده است. در حالی که Gemini 1.5 Pro به شما امکان میدهد تا یک میلیون توکن را بارگیری کنید (در پیشنمایش)، Claude 3 Opus با یک پنجره زمینه از 200 هزار توکن ارائه میشود. بر اساس یافتههای داخلی NIAH، مدل Opus سوزن را با بیش از 99 درصد دقت بازیابی کرد.

در آزمایش ما با تنها 8 هزار توکن، Claude 3 Opus نتوانست سوزن را پیدا کند، در حالی که GPT-4 و Gemini 1.5 Pro به راحتی آن را در طول آزمایش ما پیدا کردند. ما همچنین تست را روی غزل کلود 3 انجام دادیم، اما دوباره شکست خورد. ما باید آزمایش های گسترده تری را در مورد مدل های Claude 3 انجام دهیم تا عملکرد آنها را بر روی داده های طولانی مدت درک کنیم. اما در حال حاضر، برای Anthropic خوب به نظر نمی رسد.
برنده: Gemini 1.5 Pro و GPT-4
7. فیلم را حدس بزنید (تست بینایی)
Claude 3 Opus یک مدل چند وجهی است و از تجزیه و تحلیل تصویر نیز پشتیبانی می کند. بنابراین ما یک عکس از نسخه نمایشی Gemini گوگل اضافه کردیم و از آن خواستیم فیلم را حدس بزند. و جواب درست را داد: صبحانه در تیفانی. آفرین به آنتروپیک!
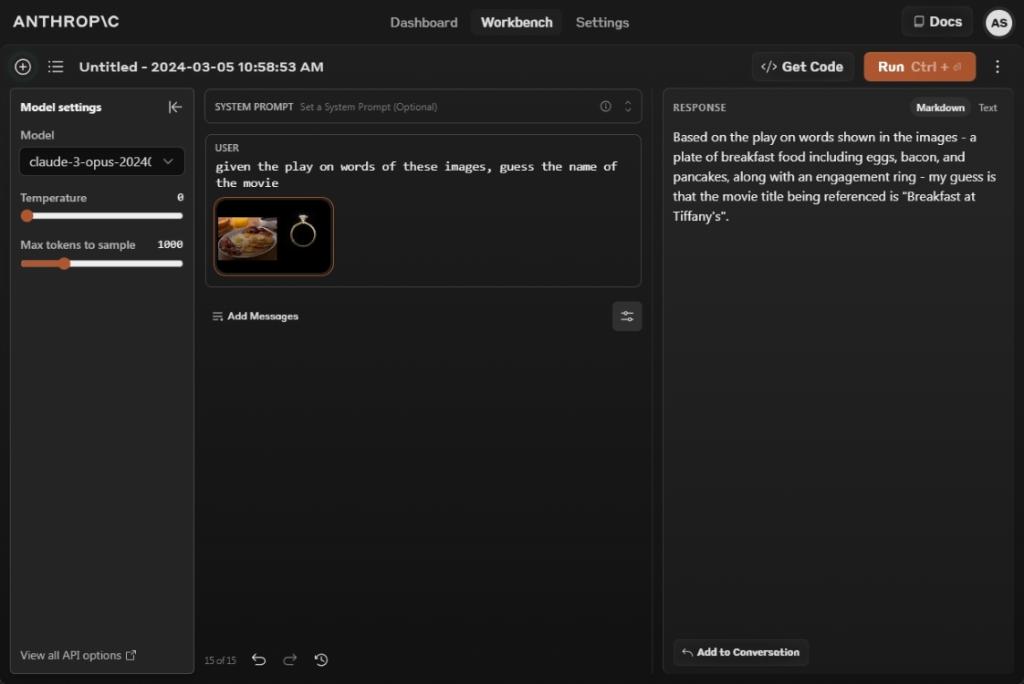
GPT-4 نیز با نام فیلم مناسب پاسخ داد، اما عجیب اینکه Gemini 1.5 Pro پاسخ اشتباهی داد. من نمی دانم گوگل چه چیزی درست می کند. با این وجود، پردازش تصویر Claude 3 Opus بسیار خوب و در حد GPT-4 است.
given the play on words of these images, guess the name of the movie
برنده: Claude 3 Opus و GPT-4
حکم
پس از آزمایش یک روزه مدل Claude 3 Opus، به نظر می رسد یک مدل توانمند است، اما در کارهایی که انتظار دارید برتری داشته باشد، لنگ می زند. در تست های استدلال عقل سلیم ما، مدل Opus عملکرد خوبی ندارد و پشت سر GPT-4 و Gemini 1.5 Pro قرار دارد. بهجز پیروی از دستورالعملهای کاربر، در NIAH (قرار میرود مناسب آن قوی باشد) و ریاضیات خوب عمل نمیکند.
همچنین، به خاطر داشته باشید که آنتروپیک امتیاز بنچمارک Claude 3 Opus را با امتیاز گزارش شده اولیه GPT-4 مقایسه کرده است، زمانی که برای اولین بار در مارس 2023 منتشر شد. در مقایسه با آخرین امتیازات بنچمارک GPT-4، Claude 3 Opus به GPT-4، به عنوان با اشاره به توسط Tolga Bilge در X.
همانطور که گفته شد، Claude 3 Opus نقاط قوت خود را دارد. آ کاربر در X گزارش داد که Claude 3 Opus توانسته است از روسی به چرکسی ترجمه کنید (زبان نادری که تعداد کمی از آن صحبت می شود) فقط با یک پایگاه داده از جفت های ترجمه. کوین فیشر در ادامه به اشتراک گذاشته شده است که کلود 3 فهمید نکات ظریف فیزیک کوانتومی در سطح دکترا. کاربر دیگری نشان داد که Claude 3 Opus یاد می گیرد حاشیه نویسی انواع خود در یک شات، بهتر از GPT-4.
بنابراین فراتر از پرسشهای معیار و دشوار، حوزههای تخصصی وجود دارد که کلود 3 میتواند بهتر عمل کند. بنابراین ادامه دهید، مدل Claude 3 Opus را بررسی کنید و ببینید که آیا با جریان کاری شما مطابقت دارد یا خیر. اگر سوالی دارید، در قسمت نظرات زیر با ما در میان بگذارید.






{kind=link}